

今日やった事がまさにそうかも>< わりとどうでもいい部分の最適化について疑問を持ったので仮説を立ててコードを書いてみて実験し、もしかしたら比較したコードに無駄があったせいかもしれないと考えて予想を立ててさらに改良しまた比較する><
結果が出ても「別のアルゴリズムであれば違うのかもしれない>< ロジック回路のテクニックで応用できるものは無いか?><」って調べたり><
かなり前に大学の先生が講義してくれた「分からないこと」に対するスタンスが生活の中でとても効いてきている - Togetter https://togetter.com/li/2109712
これ、オレンジの発想のまるっきり反対だし、オレンジが多分野に詳しくなれたのはこれと正反対の発想で、答えを得る為に全力で調べて「なにか見逃している要素はないか?><」「自身の知識も全て活かせているか?><」って自分を追い込みながら仮説を立てて、その仮説が正しいのかさらに調べ続けて答え合わせをしていって、誤っていた場合「どうして判断を誤ったのか?><」「どういった要素を見逃していたのか?><」ってPDCAグルグル回しまくりで進めていってるからこそって言えるかも><
実験してどうでもいい部分の高速化遊んでたから、本来の目的のコードが全然進んでない・・・・><;
ていうか、0だったら0のままで0以外だったら全bit立てるって命令があったらいろいろ高速化に便利だと思うんだけど、そういうのある環境って無いのかな?><;
こういうレアケース(?)に限って言うと、回路が十分に高速であれば、現代のPC向けCPUでもコネクションマシンのアーキテクチャのコプロセッサ(というかなんと言うか)をくっつけて高速化に利用できるのかも?><;
(柔軟なロジック回路をプログラミングで作れるような環境(超頻繁に書き換えまくれる版超小規模PLDのような感じ)だし><)
・・・そんなことするよりもクロックちょっとあげる方が手っ取り早いわかる><;
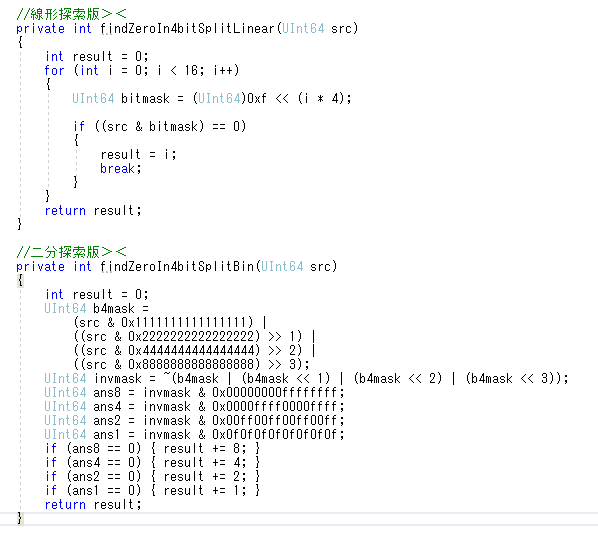
これのほかにifを全く使わない条件分岐無しバージョンも書いたけどむしろ大幅に遅くなった><;
書いてて「これがデジタル回路だったら、小さい規模の回路で一瞬で結果が出るのに!><;」って思った><;
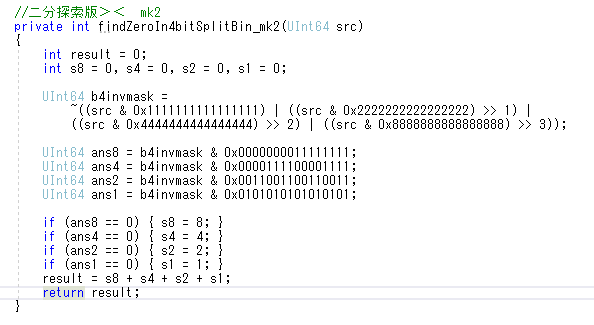
二分探索版を無駄な計算無くして並列実行されやすい気がするように(?)リファクタリングしたら、最適化コンパイルしても線形探索版とどっこいどっこい(測るたびに勝ったり負けたりする程度)まで速くなった><
{kind=link}
二分探索のコード、if使ってる部分がどう考えてネックになりそうだから、そこを論理演算使うように書き換えたらまた追い越せるのかな?><;
命名が微妙におかしいのは実験コードだからで許してほしい><;
{kind=link}
ていうか最適化コンパイルでは
↑速い
while使ってきれいに書いた線形探索
二分探索
forを使った無駄がある線形探索
↓遅い
なので、最適化で追い越したのはきれいに書いた版だけってことかも><
ちなみに、無駄にforで処理してたのをwhile使うようにきれいに書き換えたのは、最適化コンパイルをしてもちゃんと高速化されてる><
(そういう無駄な書き方してる部分のリファクタリングはちゃんとやった方がいいよだよね><)
ちゃんとオチがついた><;
"早すぎる最適化は諸悪の根源である。" ドナルド・クヌース
(オレンジ意訳「変に手動でコードを最適化すると、未来のCPUやコンパイラの最適化を邪魔して逆に遅くなったりするよ!」)
・・・・これそのまんまじゃん><
!!!!!><
最適化コンパイルすると線形探索の方が速くなる!!!!!!!><;
線形探索版の方を無駄を減らしてwhile使うようにリファクタリングしたら、処理時間5パーセント~10パーセント程度削減できたけど、それでも二分探索版よりも遅い><
線形探索版、while使うようにして無駄を減らしたら速くなる・・・?><;
実験に使ったコード><
下の方が8割の時間で処理が終わるって、ほんと不思議><;
「がんばっても無駄でした!><;」ってオチになると思って書いたのに><;
{kind=link}
https://mstdn.nere9.help/@orange_in_space/110088685897843278
こんななんかむしろ処理が増えてそうなコードでも、百万回試行で処理時間見比べるのを何度も繰り返してみたら、だいたい8割くらいの時間で終わるっぽい><
不思議><
- @orange_in_space
2017年 4月に登録
