

二分探索のコード、if使ってる部分がどう考えてネックになりそうだから、そこを論理演算使うように書き換えたらまた追い越せるのかな?><;
命名が微妙におかしいのは実験コードだからで許してほしい><;
{kind=link}
ていうか最適化コンパイルでは
↑速い
while使ってきれいに書いた線形探索
二分探索
forを使った無駄がある線形探索
↓遅い
なので、最適化で追い越したのはきれいに書いた版だけってことかも><
ちなみに、無駄にforで処理してたのをwhile使うようにきれいに書き換えたのは、最適化コンパイルをしてもちゃんと高速化されてる><
(そういう無駄な書き方してる部分のリファクタリングはちゃんとやった方がいいよだよね><)
ちゃんとオチがついた><;
"早すぎる最適化は諸悪の根源である。" ドナルド・クヌース
(オレンジ意訳「変に手動でコードを最適化すると、未来のCPUやコンパイラの最適化を邪魔して逆に遅くなったりするよ!」)
・・・・これそのまんまじゃん><
!!!!!><
最適化コンパイルすると線形探索の方が速くなる!!!!!!!><;
線形探索版の方を無駄を減らしてwhile使うようにリファクタリングしたら、処理時間5パーセント~10パーセント程度削減できたけど、それでも二分探索版よりも遅い><
線形探索版、while使うようにして無駄を減らしたら速くなる・・・?><;
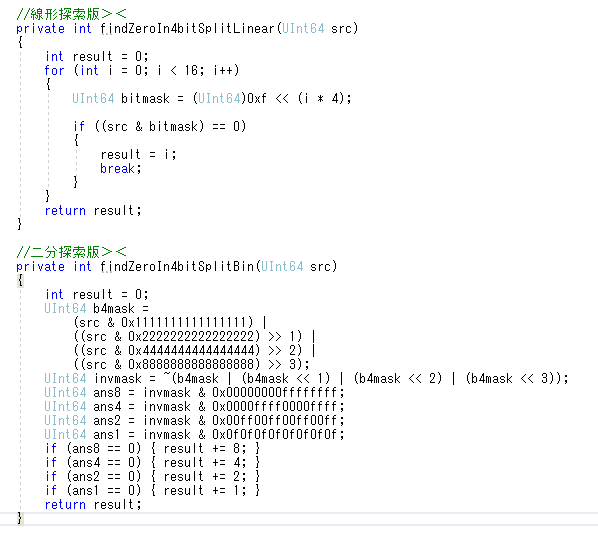
実験に使ったコード><
下の方が8割の時間で処理が終わるって、ほんと不思議><;
「がんばっても無駄でした!><;」ってオチになると思って書いたのに><;
{kind=link}
https://mstdn.nere9.help/@orange_in_space/110088685897843278
こんななんかむしろ処理が増えてそうなコードでも、百万回試行で処理時間見比べるのを何度も繰り返してみたら、だいたい8割くらいの時間で終わるっぽい><
不思議><
{kind=link}
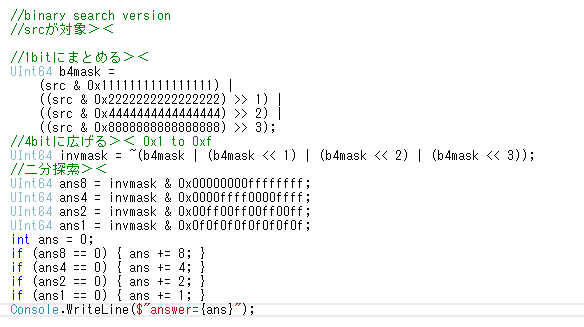
0b00010001、左シフトして0b00100010..
みたいなマスクを使って結果を右シフトしてorしてって4回やって1bitにまとめれば二分探索できる?><;
どう考えても処理増えそう><;
4bitに区切った各桁を全部で4回andしてどうにかするような手で高速化されるのかな?><;
実際の処理で言うと、64bit unsigned intに4bit区切りでIDが書かれていて、空のマスの場所は4bitが0になってる><
これを探すのって結局4bitずつbitマスク(0xf)をずらして0になる場所を探す線形探索するしかない?><
検証用コード書こうとして気づいたけど、この場合は二分探索の方が処理増えるというか二分探索出来ない?><;
富豪的発想「そんなごくごく小さな処理の重さなんて気にせず書きやすく読みやすい方で書け」
><;
15パズルのパネルのマップから空いてるマスを探すのって、端から探してくのと二分探索するのどっちが軽いんだろう?><(実験しないとわかんない?><;)
- @orange_in_space
2017年 4月に登録
