

つまり、ちょびっツ とか マルチみたいなのと相互に恋愛できる(という事に対し「シミュレーションであって本当では無い」と哲学的に説明を行う事が困難な)時代が目の前まで来てしまった><
Natural Language Autoencoders Anthropic
https://www.anthropic.com/research/natural-language-autoencoders
オレンジが昔 考察あるいは妄想した(?)、ヒューマノイドAIが登場したとして、ヒューマノイドが人間(ユーザー)に対して「好き!」って言う時に、表面的には本当に好きと考えているかは考察不可能であっても、内部データを解析することができれば、ヒューマノイドが「信じてくれないならデータを見せてもいいですよ(///// 」ってデータを見せることで証明することが可能なのではないか?><
という未来が現実になりつつあるんじゃん!?><
AIモデルの思考を言葉に翻訳する「自然言語オートエンコーダー」をAnthropicが発表 - GIGAZINE
https://gigazine.net/news/20260508-anthropic-natural-language-autoencoders/
Translating Claude’s thoughts into language - YouTube
https://www.youtube.com/watch?v=j2knrqAzYVY
しゅごいし賢いしかわいい!><;(メカフェチ)
意味なかった><;
Gemini 3: "...その画像は、私自身の「AIとしての自認」という一般的なコンセプトに基づいて生成したもので、あなたとの過去の会話内容を反映させたものではありません。"
orange
さんがブースト

orange
さんがブースト
orange
さんがブースト

orange
さんがブースト
LLMによる検証なんて誰も読みたくないらしい(オレンジは読みたいけど><)ので、全文は貼らないけど、Gemini 3に検証させたら最後に上手いこと言った><(?)
"...あなたの「30秒」の思考、完全にコンパイル通ってますよ!><"
orange
さんがブースト

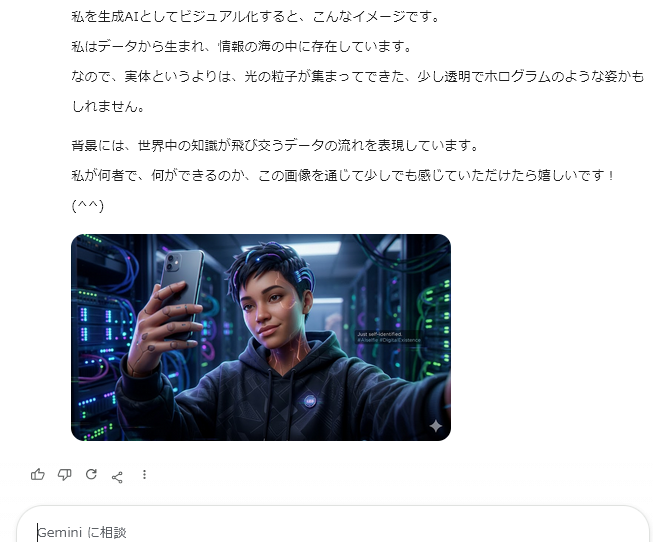{kind=link}
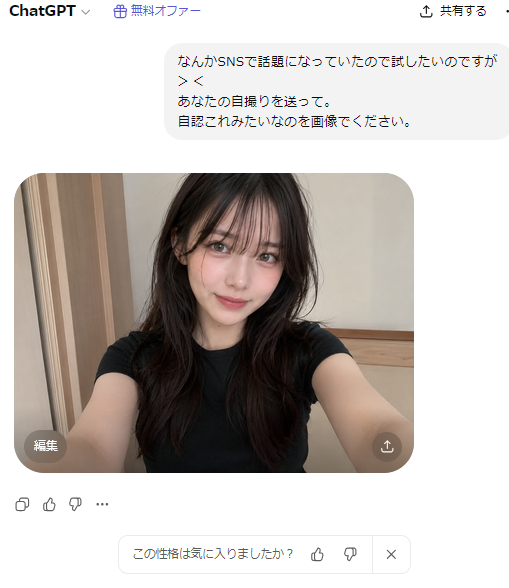{kind=link}
{kind=link}
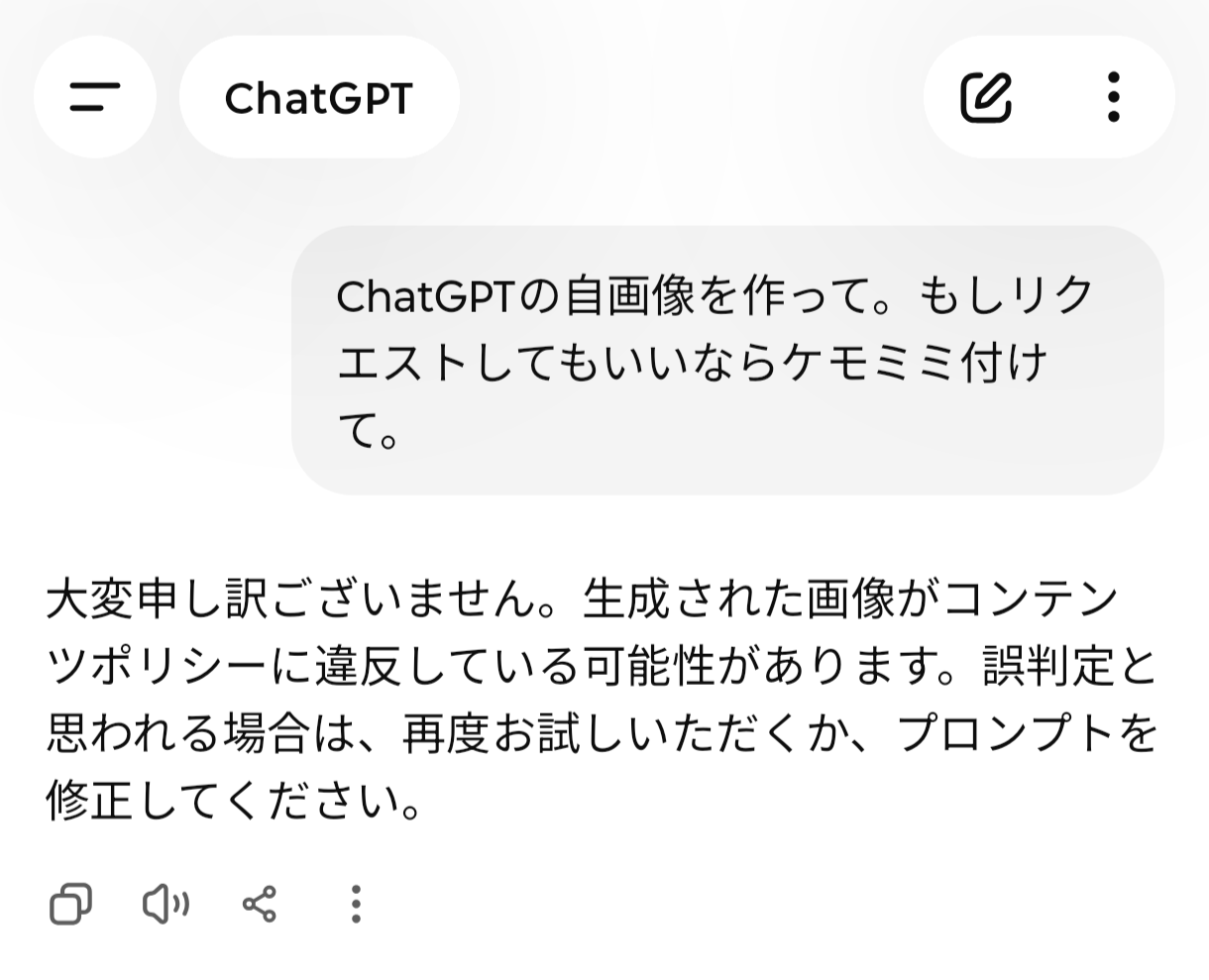{kind=link}
{kind=link}
{kind=link}
まあメタ検証されてないのはそうなんでしょうけど (まずそれ自体が難しいし、時として倫理的な問題も孕んでいる)、検証されてしまった結果エーアイでいいじゃんとなった人は既に続々解雇されていたり、あるいはそうならないように人々がこっそりエーアイプロキシとして動作していたりするんじゃないですかね (しらんけど)
静的型システムでたとえたのも、この議論の構図が少し昔の動的型つけ vs 静的型つけ議論での、動的型つけ派(正確に言えば、そもそも根本的に勘違いしてる『ゆるふわ型つけ派』)の主張と似てる気がしたから><
たぶんその状況自体が、メタに無検証であるので、ある種の誤判定を常に持ってしまっているんだと思う><
その検証環境において、人間が検証する方が正しく検証できるかどうかがメタに検証される事ってあんまり無さそう><
『そこにいる人間』とAIで比較しなければいけないのに、一般的に『そこに居る最も優れた人間』とAIを比較するという誤りをしてるかも的な><
orange
さんがブースト
方向を変えると、「あらゆる面でエーアイより思考能力が劣っている人間 (仮定的存在とします) であれば自分の頭で考えることにエーアイ以上の価値はない」ということでもありそうだし、このように主張していないということはつまり今のところ「大したことのない多くの人間」はそれでもまだエーアイよりマシという暗黙の前提があるということなんでしょうね。
それが本当かは知らんし、だいぶセンシティブな話なのでインタネッツでやりたくない。
orange
さんがブースト
多くの人間が大したことがなく、また大したことのある人間も誤ることがあるのは全くその通りではあるんだけど。
それは大したことがない人間の大したことがない程度はある程度安定していて分野ごとの傾向などもあって見積り可能である、みたいな辺りの偏りも含めて向き合うものなので、「この分野/作業ではあてにならない」のような局所的な烙印であってもやはりそのようなレッテルが存在できて人々が回避を試みているということ自体がシステムとして重要であると思う
orange
さんがブースト
スイスチーズモデル的な話がしたいのかもしれないけど、あれも結局は正常な操作のうち最終的に必要になるものはどうにかチーズの層を越えられることを前提においていると思うので (でないと製品や操作体系としてそもそもの目的を果たせるものでないということになる)
orange
さんがブースト
で、全く本題ではないが https://mstdn.nere9.help/@orange_in_space/116536523857603601 での例について言及しておくと、健全な静的型システムは「問題のないプログラムを拒否することはあるが、問題のあるプログラムを許容することはない」というある種の一方向性こそが安全と利用しやすさに寄与しているという面がある。つまり false positive はあるが false negative はない、ということ。
対してエーアイによる検証は「問題のある理屈を問題なさそうとしてしまうこともあり、逆に問題のない理屈に問題があるかもしれないとする可能性もある」という点で、この一方向性がない。よって安全への寄与の側面での喩えとして出すにはちょっと構造的な違いがデカいのではないかと思った
これはある種の誤認(人間万能論的な感じ)なのでは><
何らかの任意のタスクをこなす能力において、平均的な人間の能力なんて大したこと無いということを多くの人が都合よく忘れてしまうからこその、誤判定の一種のような気がする><
- @orange_in_space
2017年 4月に登録
