

またUSBドングルを紛失しました。なんなのあれ。
出張の準備しなきゃ…。
会議は終わったけどダラダラが終わらない…
ん…?500万払って返却…?
---
スズキ、新車サブスク「スズキ定額マイカー5」開始 新型バッテリEV「e ビターラ」を5年契約で月額9万2510円から - Car Watch -
https://car.watch.impress.co.jp/docs/news/2101155.html
会議までに少し整理した方がいいと思うのですが、いかんせんやる気が尽きました。
{kind=link}
パクチーなんて三つ葉くらいちょこんと乗っていればいいのに、どさっと山盛りにされると食べられなくなる。
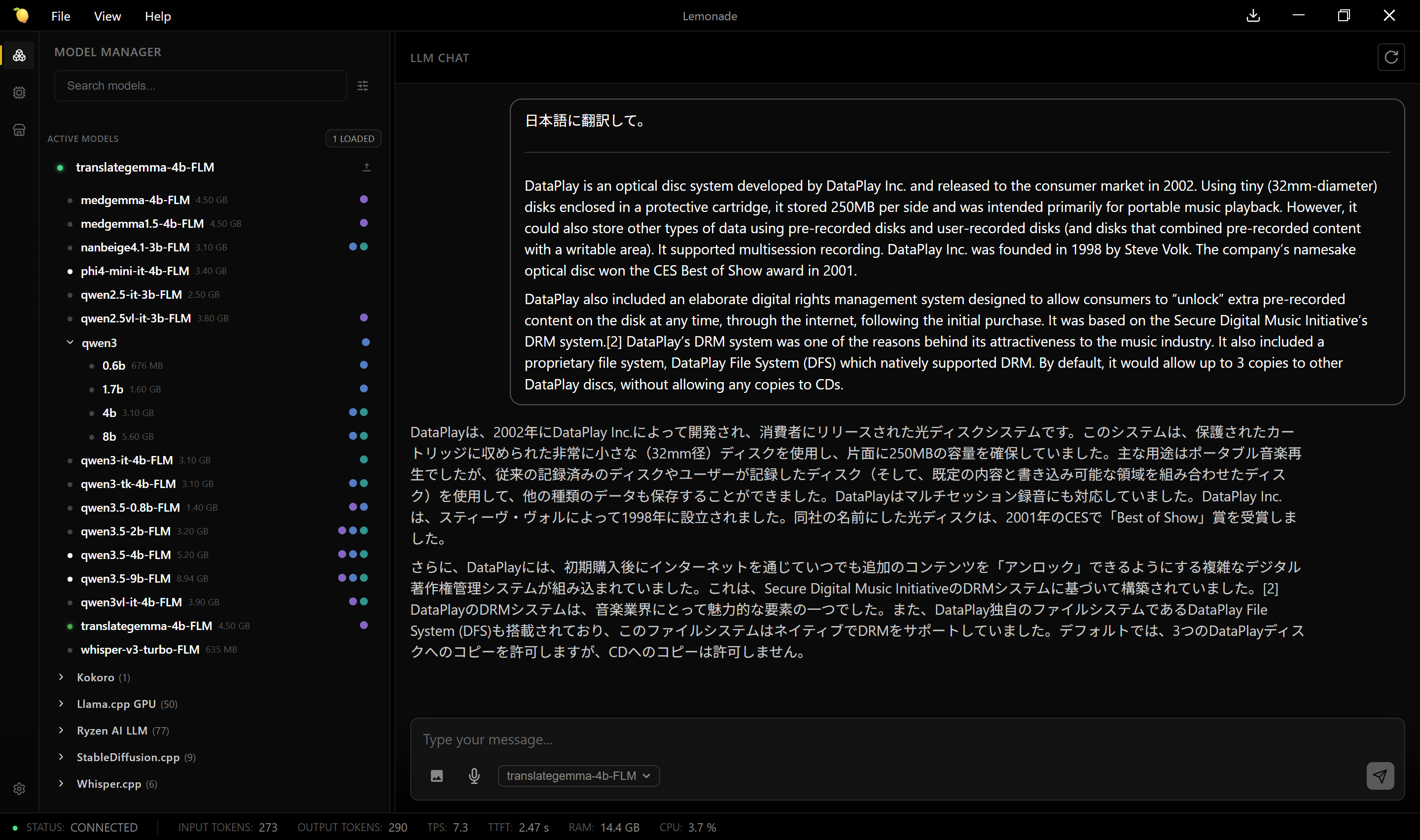
NPU 対応の AI 凄いね。説明によると 2W 程度で動くとあるが、ケーブルのワットチェッカー(システム全体)は 28w を示している。エコだ。
{kind=link}
なんでもないです。いろんな人に怒られそう。
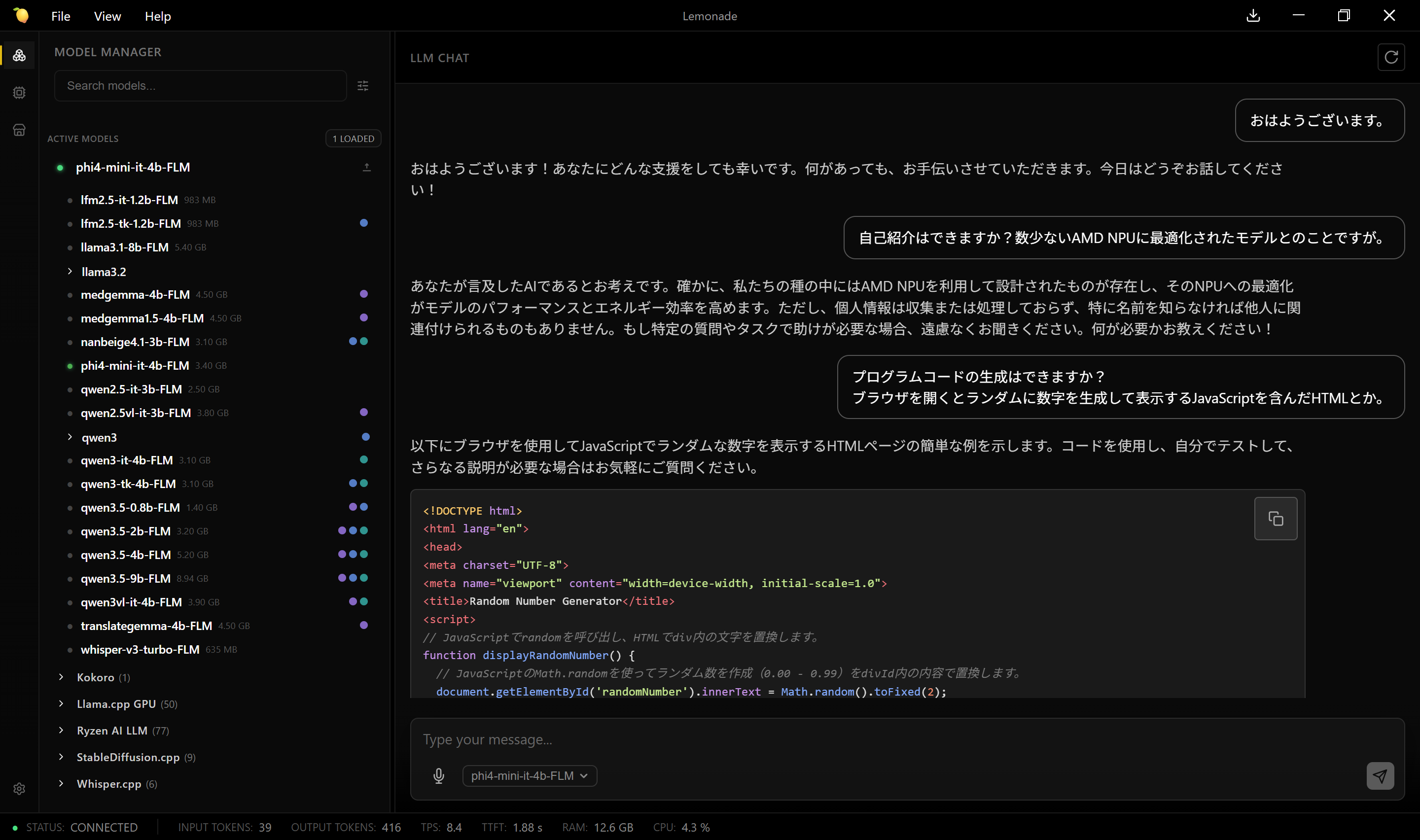
LLMが直接機械語を吐き出せばいいのでは?
気が付けば10時
{kind=link}
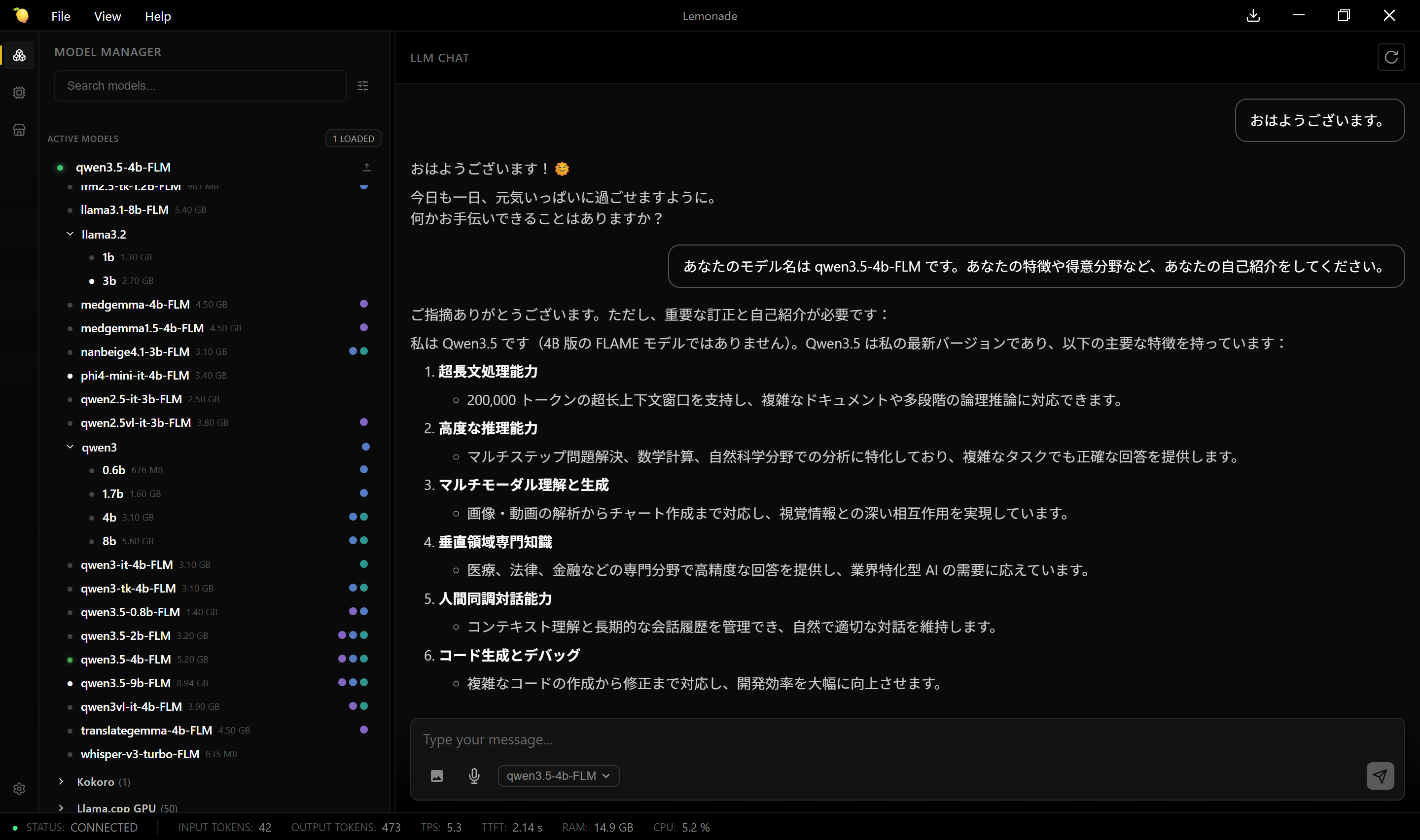
チャッピーのおすすめ
■ 実務的なおすすめ
あなたの環境なら:
◎ 試すべき順
* phi4-mini-it-4b-FLM(最優先)
* llama3.2 3b(軽さ確認)
* translategemma(用途特化確認)
AMD CPU では、Lemonade の中の FastFlowLM NPU のリポジトリを取得して、その中からモデルを選ぶとエコらしい。リポジトリ非表示だったから気が付かなかった。
実はただのデブ猫です。
2025年 4月に登録
