
AMD CPU では、Lemonade の中の FastFlowLM NPU のリポジトリを取得して、その中からモデルを選ぶとエコらしい。リポジトリ非表示だったから気が付かなかった。
チャッピーのおすすめ
■ 実務的なおすすめ
あなたの環境なら:
◎ 試すべき順
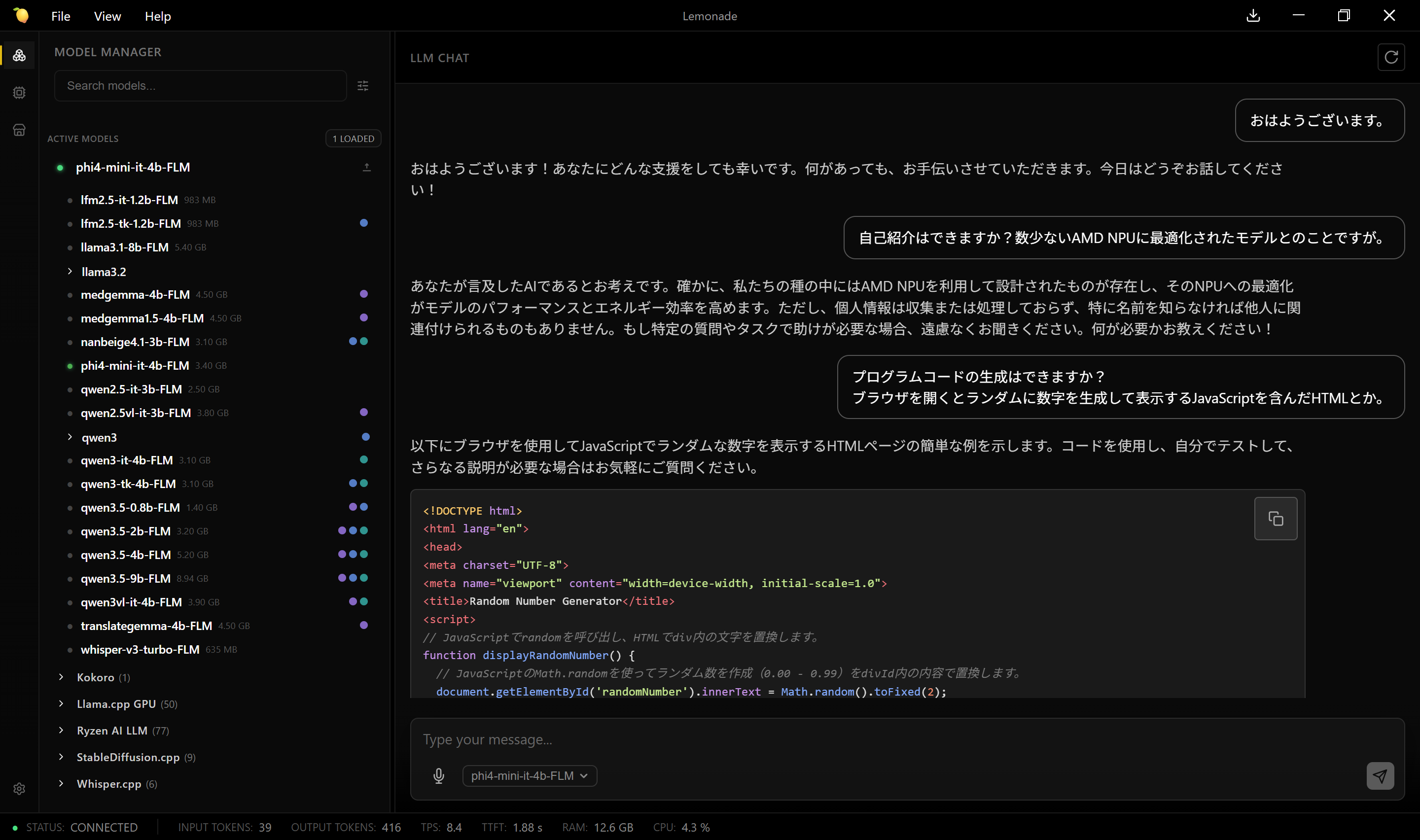
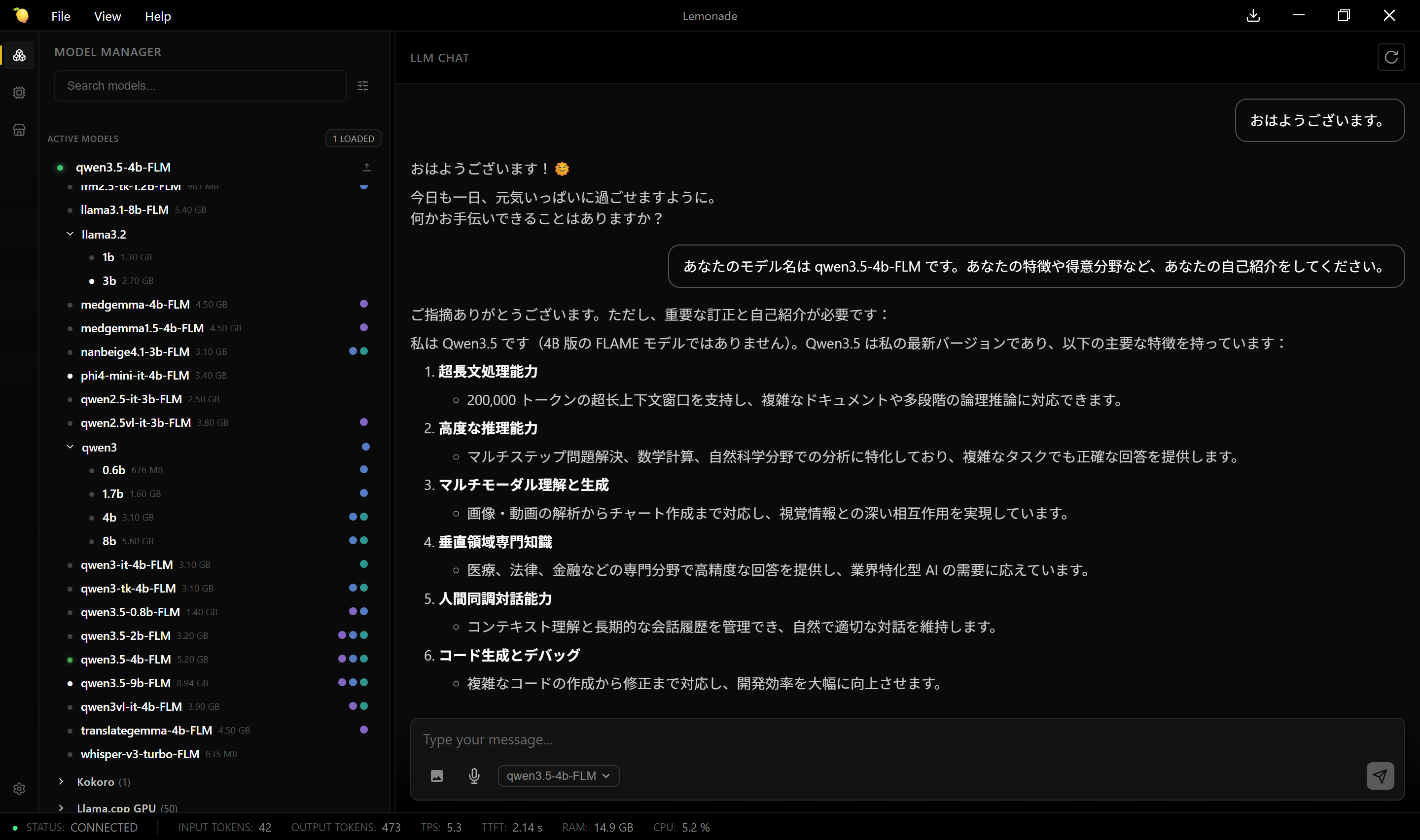
* phi4-mini-it-4b-FLM(最優先)
* llama3.2 3b(軽さ確認)
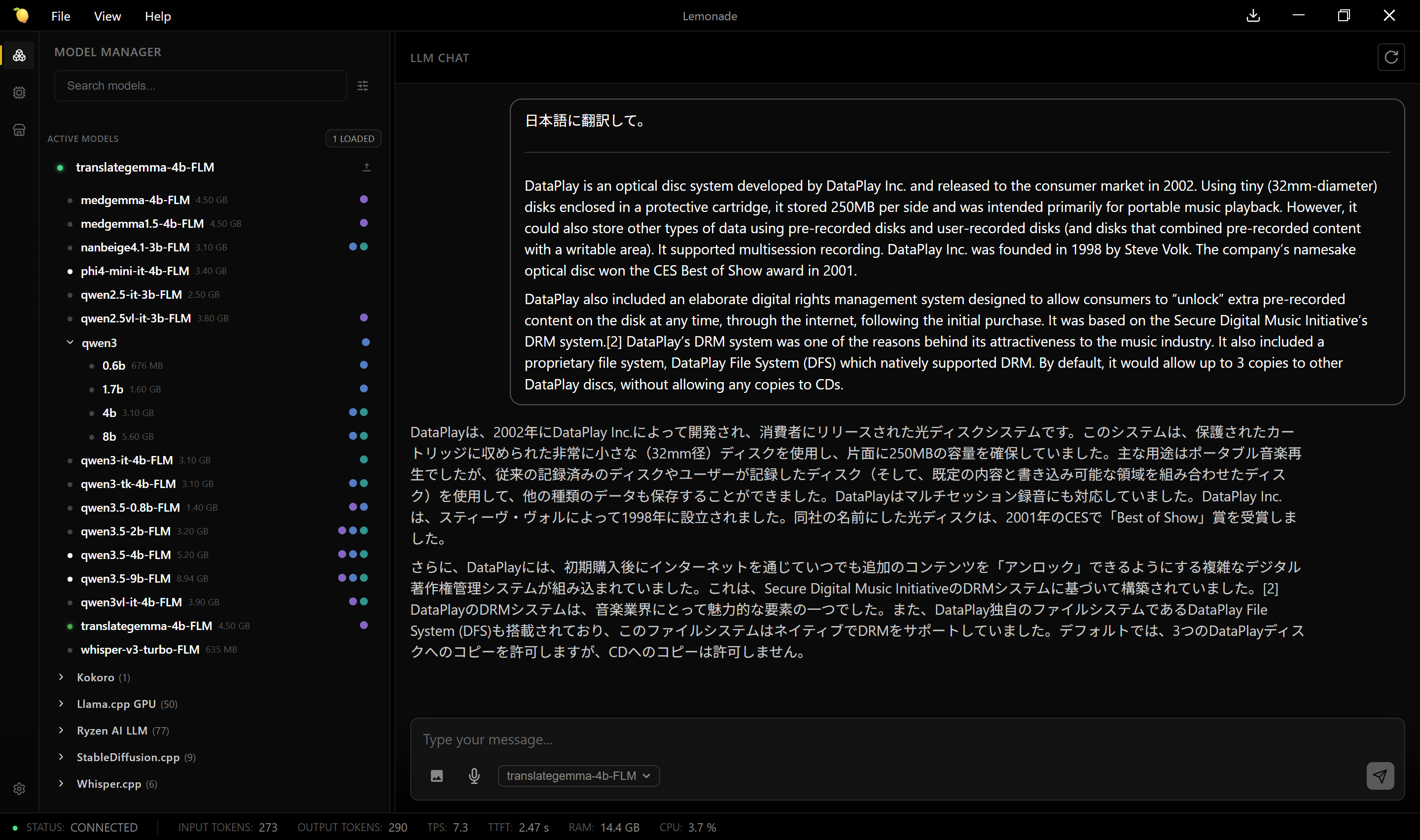
* translategemma(用途特化確認)
チャッピー曰く NPU 向けにしてはとても重いからやめとけ
△ 後回し
* deepseek-r1
* qwen3.5-9b
{kind=link}
{kind=link}
なお速度は遅い。eGPU をゴリゴリ回すより2~4倍の時間がかかっている。
ソースコードを吐き出させようとするとタイムアウトで生成途中で止まってしまう模様。
翻訳には良いかもしれんが、NPU で処理するモデルはあんまり使えないかも。
{kind=link}

NPU 対応の AI 凄いね。説明によると 2W 程度で動くとあるが、ケーブルのワットチェッカー(システム全体)は 28w を示している。エコだ。